



The LLM That Could Beat ChatGPT
Using 5 playbook strategies from two tech tales: iTunes vs. Napster and Early Google vs. Lycos, Excite and Infoseek

The LLM race looks finished.
ChatGPT sits on the throne.
Claude charms devs.
Google plays both sides—consumer and enterprise.
Meta’s AI powers its walled garden of billions.
But history says the real LLM champ might still be in stealth:
10-Second Takeaways from this Article
The Next ChatGPT Might Be in Stealth Mode — Just like Google quietly beat early search giants and iTunes leapfrogged Napster, a dark horse LLM can still win.
How to Beat Today’s Leaders — Build a clean-sheet LLM that:
• Pays for premium content
• Proves every source
• Gives creators a 70% cut
• Offers IP indemnity
• Embeds into everyday tools (apps, hardware, APIs)

The New LLM Can Leverage these 2 Classic Plays
There are two stories from tech history worth reviewing for who the new winning LLM might be.
Early Google (1998-2000) — Google didn’t launch until 1998—four years after the well-funded search darlings Excite, Lycos, Infoseek, and AltaVista.
Google beat them with things like:
Page Rank (a formula for higher quality content results cuz it was by citations)
Volume of Content (they indexed more of the web)
Monetization for Publishers (AdWords (October 2000) let web sites drive traffic to themselves and make tons of money; and later AdSense (June 2003)) — Google paid publishers to put ads on their sites.
iTunes Creating the Legal Napster (2003)
Today’s LLM leaders are encircled by lawsuits (NYT, Reddit, Ziff-Davis, even Taylor Swift).
These lawsuits remind me a lot of what happened to Napster.
In 1999, Napster was huge (80 mil. users (equivalent to 800 mil. today!). By 2001 the music labels sued and shut it down.
By 2003, Apple (then only worth $6.7B) seized on the gap, made deals with the five big labels, sold songs for 99 cents, and iTunes won the market.
iPod/iPhone/App Store — iTunes fueled iPod sales, won music industry trust, and primed users for the iPhone and App Store—launching Apple’s digital empire.
Note: Napster was taken down in 24 months.
Note: We’re only 30 months into the “LLM Wars” if you count Day 1 as ChatGPT’s debut in November 2022. And the Early Google and iTunes story played out in the 2 to 4 year timeframe.
So, using those 2 stories, here’s how a new LLM could take ChatGPT et al down.
1) Turn AI’s Copyright Chaos into Your Competitive Moat
Go Legit So You’re Not “The next Napster”
Today’s AI giants are in court with The New York Times, Reddit and many others over unlicensed data.
A clean-sheet model that pays for content (like how Apple’s iTunes supplanted Napster) can grab the trust they are losing.
Do these things—simple, but powerful:
License key data before launch. Sign newsrooms, studios, and niche experts so your model trains on “legal gold,” not pirate loot. Tons of content
Show your sources. Add footnotes and links like Google’s old PageRank signals—facts, not guesses.
Pay creators a cut. Copy iTunes’ 70-percent split. When writers and labels get paid, they cheer for you.
Uncapped IP Indemnity — Promise “we cover the legal bills” the way IBM’s Granite 3.0 model offers uncapped indemnity.
Publish an ethics dashboard. Let anyone see what data you used, who got paid, and how to opt out.
Nail these steps and legal fears turn into your moat—big buyers will call you first because you’re the safe bet.
And, marketing/positioning-wise, you can position ChatGPT, Claude, Gemini et al as “The Napster LLMs”
2) Fill Your Model With Golden Content
Start with the free web, then lock up the gems.
Big wins need big data (what us creators call content).
Google beat the portals by crawling more pages. iTunes beat CD stores by stocking every hit song.
Your LLM must do both jobs at once:
Bucket 1: The Open-Web Core
These sets cost nothing but give huge reach
For example, IBM was able to get 15 trillion+ tokens of data for its Granite 3 model through this content:
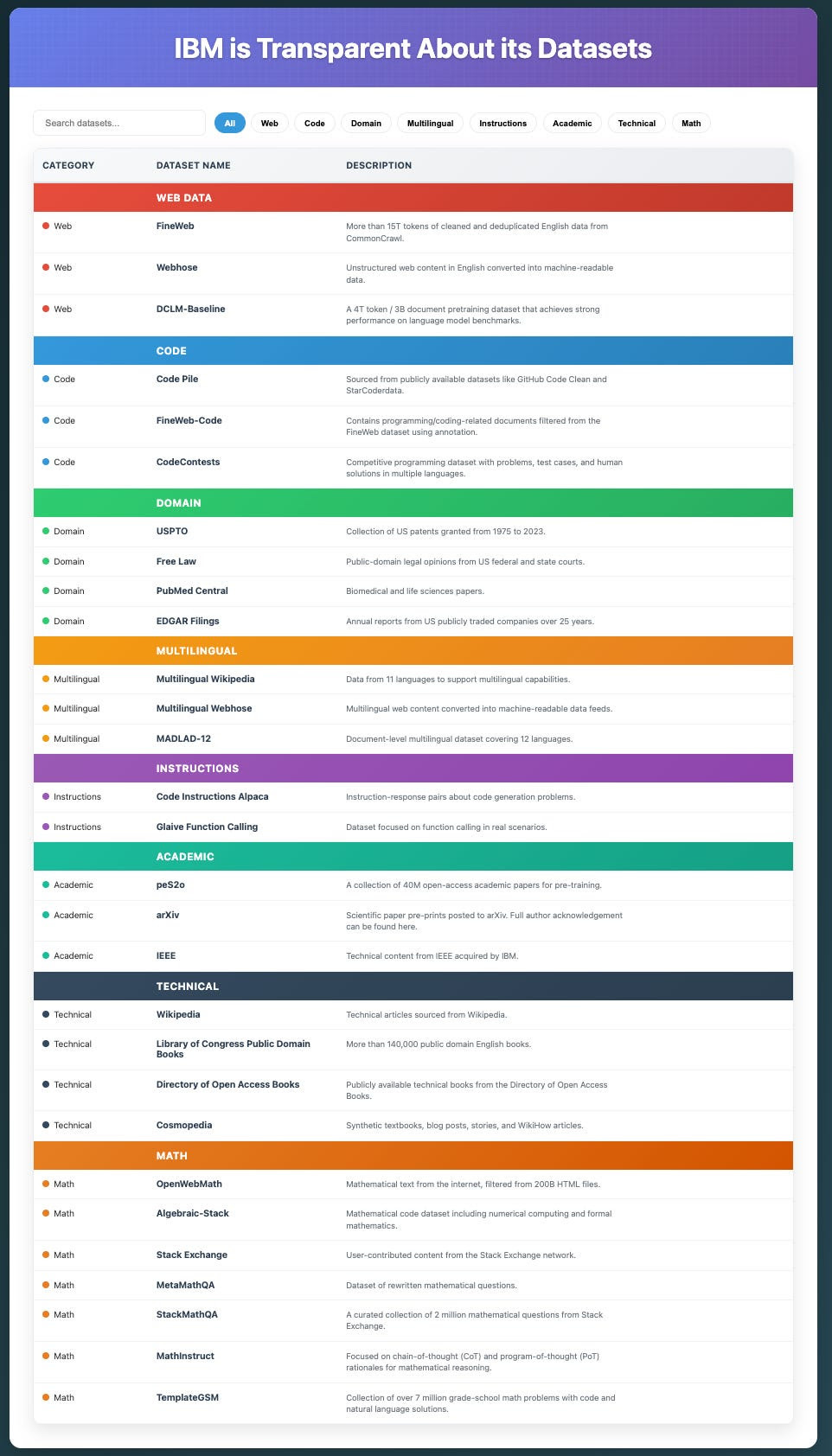
This “public stack” is wide, clean, and lawsuit-free.
Bucket 2: The Premium Content
Pay for the hits your rivals can’t scrape. Sign at least a couple of leaders in each lane:
News: New York Times, Washington Post, Guardian, Gannett, Axios, AP, Reuters
Magazines: Dotdash Meredith (People), Hearst (Cosmo), Condé Nast (Vogue)
Academic: Elsevier, Springer Nature, Wiley, Taylor & Francis
Music: Universal, Sony, Warner plus indie hubs like The Orchard
Film & TV: Disney, Warner Bros Discovery, NBCUniversal, Paramount
Images & Clips: Getty, Shutterstock, Freepik
Community: Reddit, Stack Overflow, Automattic blogs
Here are examples of Content Licensing Deals I know about with estimated costs per year to license the content:
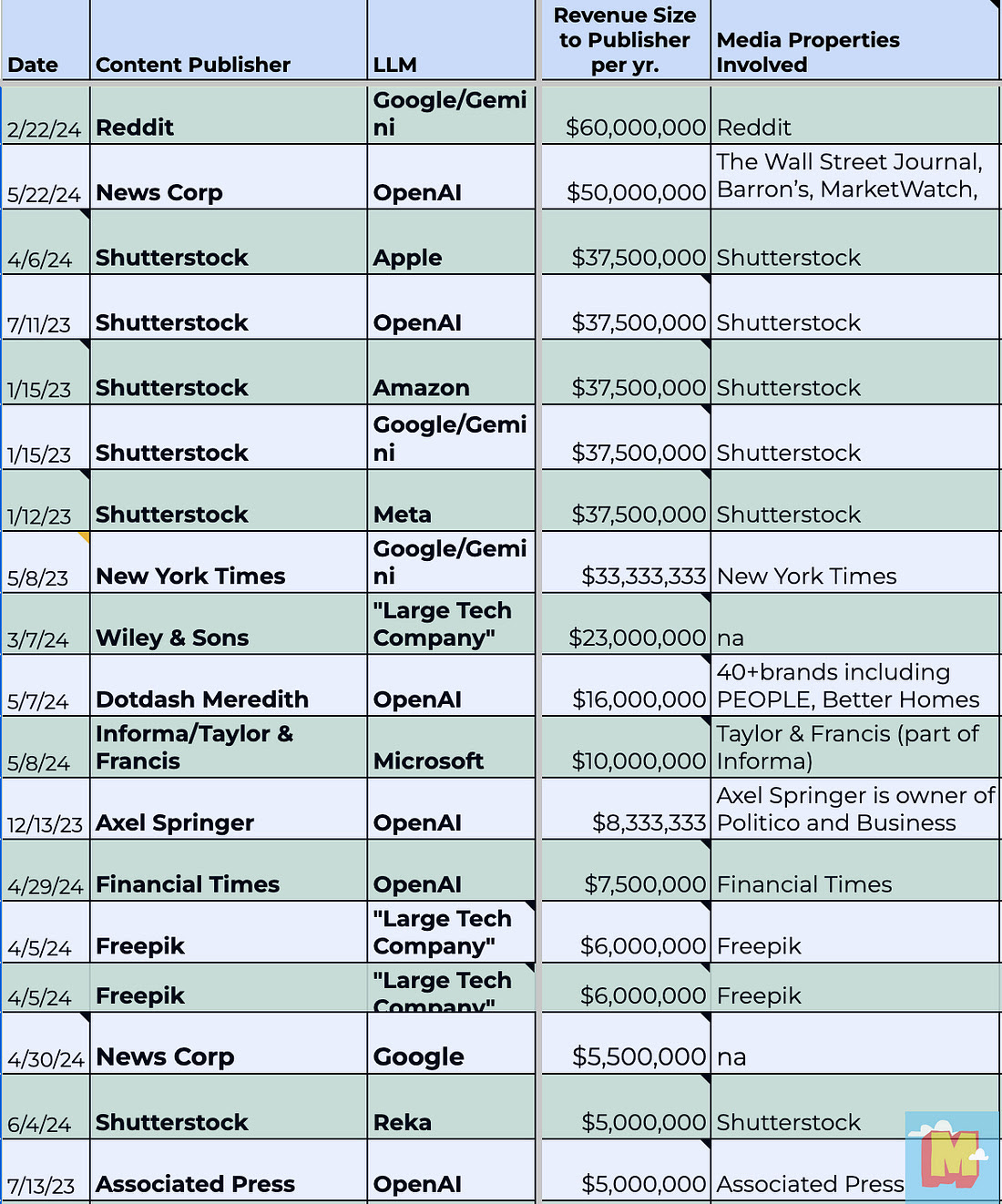
Write big checks and you can own the words, songs, and scenes for years.
Now your model can quote from the Times, sing a Beatles verse, or cite a new cancer study—legally.
There are More Buckets of Content Every Day
For those of you who say existing LLMs are trained on almost all the data there is, that’s a crock.
There are endless supplies of new content created every day:
All Real-time data — anything happening right now has not been trained on. Think live action stuff such as anything recorded by autonomous vehicles.
New Device Data — Any new recordings from cars w cameras, Ring Cameras, watches, smart glasses, pendants, etc. is not yet trained on.
New Weather Data — Every new storm, wildfire, etc. is untrained on
Underwater — Only a small amount of data on what goes on underwater is trained on.
Biology — The data in all our bodies and cells is relatively untapped.
Space — The Universe is endless so there’s plenty more out there that will be trained on in the future…but isn’t now.
3) Prove Your Sources with Radical Transparency of Datasets
Radical Transparency Beats Hallucinations
In 1998 Google beat larger search sites with one simple trick: it ranked pages by who linked to them (PageRank) and let users click the source.
People could see why a result was on top and trust it.
Large language models often “hallucinate”—they make things up.
That scares banks, doctors, and teachers. Analysts say sloppy or hidden data is a big cause.
Be the model that proves every word. Here’s the play:
Open the training log. Publish a clear list of the datasets you use (IBM already does this with Granite 3.0) and when you refreshed them.
Add footnotes. After each answer show the links you learned from so users can check your work.
Show confidence scores. Mark low-certainty lines in yellow so readers know to double-check.
Let users flag errors fast. One click sends the bad line to your team and starts a fix cycle.
Invite outside audits. Give universities read-only keys so they can test for bias and safety.
Do this and “hallucination risk” flips into your selling point.
Buyers will say, “We trust the one that shows its math.”
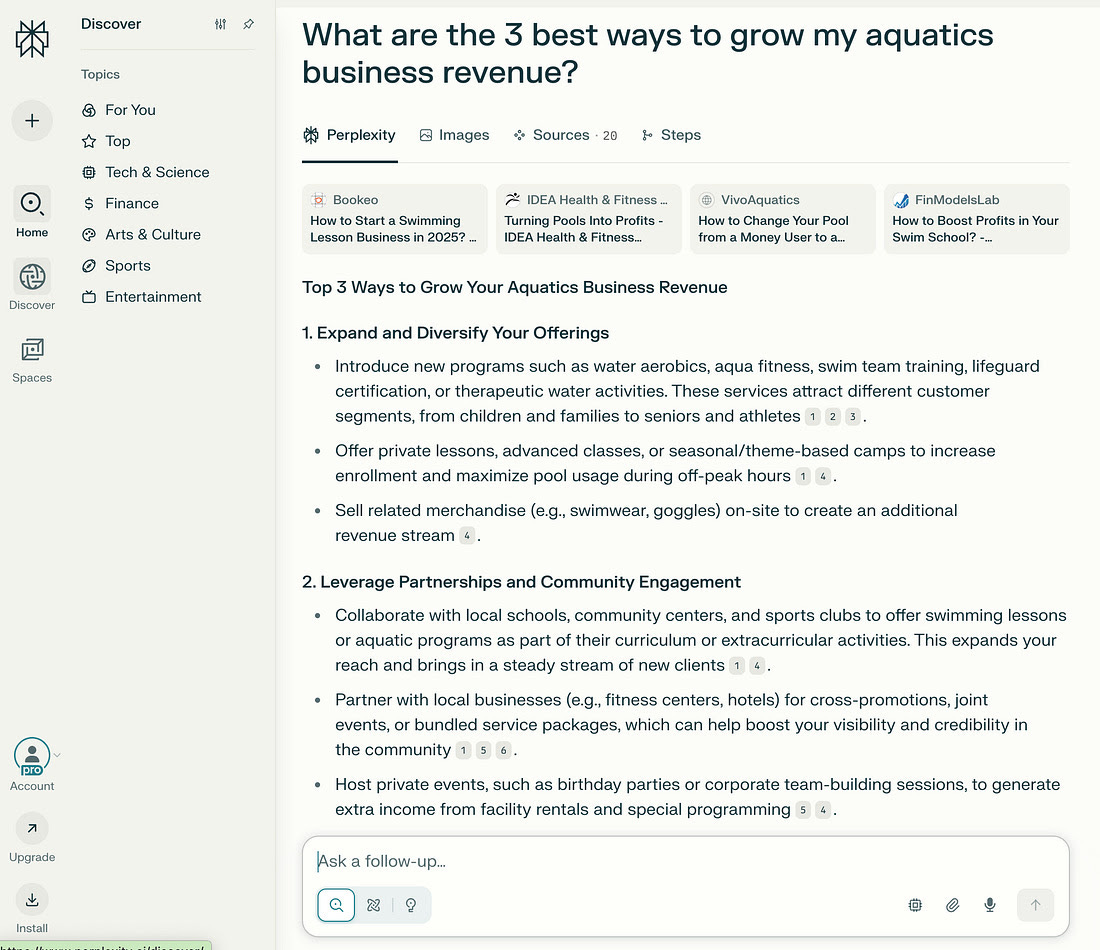
The closest type of interface you could use would be Perplexity’s where there is footnoting for answers:
There’s some movement on Fully Transparent Open-Source LLMs, such as LLM360 which describes itself as:
“an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community.”
The Most Transparent LLM Will Sell Best to the Enterprise
And being transparent gives LLMs a huge revenue advantage over LLMs with opaque datasets.
Will content companies bet the future of their new IP on LLMs with unclear datasets (and content publishers suing them) if there’s an alternative LLM with transparent datasets and “uncapped IP indemnity?
Enterprises will Prioritize Transparent LLMs
Picture a new film company that wants to use AI to help generate the movement of a new blockbuster film called Max the Monkey about a monkey named Max.
Will the film company want to create Max the Monkey IP using a tool with unknown datasets (e.g. OpenAI’s Sora or Google’s Veo) or a new tool that gives them “uncapped IP Indemnity” (IBM Granite 3.0).
IBM’s not there yet with Granite 3.0 because it doesn’t have the best training content on, say, monkey movements.
The transparent LLM can say:
“Our video gen AI tool can generate Max the Monkey’s movements based on 18 different documentaries about monkeys from the BBC, National Geo and the Nature Channel.”
If the latter can pull off a quality product (a big if), they win.
4) Pay Creators First: Follow the 70% Rule
Give the people who make the stuff most of the cash—and they cheer for you.
Apple’s iTunes sold 99-cent songs and sent about 70 cents to the music labels and artists.
Fans got easy legal music, labels got paid, and Napster faded away.
Now image sites like Shutterstock copy the move. They license pictures to AI labs ($138 million last year) and share the check with photographers.
Do the same for your LLM:
Lock a 70/30 split. Promise writers, singers, and coders 70 % of any money their work earns inside your A-I.
Show a live payout meter. Let creators see the coins tick up in real time. Trust grows when math is public.
Pay small and often. Stream micro-royalties daily, not twice a year. Fast money feels fair.
Open the door to indies. Give a self-serve portal so any blogger, band, or teacher can join and earn.
Tell the story loud. “We pay creators” is a headline every newspaper will print—because they get a slice too.
Cut in the makers first and lawsuits turn into sign-up sheets.
Spotify and YouTube also pay about 70% to rights holders for music (though YouTube pays about 55% to YouTube video creators).
Perplexity’s Publisher Program is the closest thing to this so far.
While Perplexity is not an LLM, it does reportedly share up to 25% of ad revenue with publishers whose content it uses. TIME, Der Spiegel, Fortune, Entrepreneur, The Texas Tribune, WordPress.com, Los Angeles Times, Adweek and The Independent have all joined this.
A new LLM can beat that by flipping the economic (give most (e.g. 70%) to the publisher/rights holders.
5) Own the Default Button: The Ecosystem & Integration Game
Be everywhere users already are.
Apple crushed CD stores by putting iTunes inside every iPod—one click, endless songs.
Google keeps top market share because it paid AOL and Netscape to be the default. They continue to do this today now paying Apple about $20 billion a year to stay the default Safari.
The Acquired podcast did an awesome analysis of Google’s distribution on its Google Summer 2025 episode.
Today’s AI winners copy the same move:
Microsoft 365 Copilot ships inside Word, Excel, Outlook, and Teams—no extra install needed Microsoft.
Meta AI pops up in WhatsApp, Instagram, Facebook, and Messenger, putting Llama 3 in billions of pockets.
Claude on AWS rides Amazon Bedrock into thousands of cloud accounts after an $8 billion deal.
Your checklist to win distribution
Plant flags in daily apps. Embed your LLM in email, docs, chat, and browsers first.
Bundle with hardware. Phones, wearables, cars—where the screen goes, your model goes.
Pay for prime slots. Spend on default deals (search bars, keyboards) before ads.
Open an API bazaar. Let partners build plugins that pull your model into their sites.
Sync data across the stack. One login, one history, works the same on every surface.
Do this and users won’t “choose” you—they’ll just find you waiting, one tap away.
I am fully aware that only a few companies have the potential to do this.
The Companies that Could Beat ChatGPT with a New LLM

I see 3 types of companies that could take down ChatGPT et al. These companies require vision, deep funding and execution.
The Groupings are:
Big Tech (that doesn’t already own an LLM)
Current LLMs (to Eat Their Young)
New Startup
I ballpark that the cost of creating an LLM like this would be ~$5B range (plus or minus a few $bil. depending on how much premium content they pay for).
1) Big Tech (Ones that Don’t Own an LLM)
Microsoft, Apple and Amazon all could pull this off.
They have the cash.
They have the back-end of things to sell to users of LLMs.
And all three will be in trouble if they don’t own a solid LLM.
Microsoft (the clock is ticking)
.jpg")
Microsoft is arguably in the best AI position of any company (outside OpenAI).
It owns 49% profit rights of OpenAI.
It has exclusive rights to resell ChatGPT API in the cloud (through Azure).
If a consumer or business buys ChatGPT, ka-ching, Microsoft wins.
But the clock is ticking on changes to the Microsoft/OpenAI partnership.
“Tensions are flaring” over what Microsoft’s new ownership will be when OpenAI restructures into a public benefit corporation, as reported by Berber Jin, a reporter at the Wall Street Journal.
And Steve Levy of Wired reports that Microsoft might lose its access to OpenAI’s tech when OpenAI (at its board’s discretion) determines it has reached AGI (Artificial General Intelligence).
Even Microsoft CEO Satya Nadella says things get squishy when we get to AGI.
“Fundamentally, [OpenAI”s] long-term idea is we get to superintelligence,…If that happens, I think all bets are off, right?”
A new LLM would likely be run by AI Chief Mustafa Suleyman under Microsoft’s secret MAI (“Microsoft Artificial Intelligence”) Project, as Matt Day of Bloomberg reported.
Apple (under attack)
Apple has the most to lose ($trillions) by not owning its own LLM.
Its device business has been safe for many years because its laptops, iPads iPhones and iPads are awesome entry points to consume the Web.
But they’re coming under attack in a way I’ve never seen before.
The AI Device Wars are already underway with three major LLM pitching alternatives
Meta has sold 2 million Meta Smart Glasses (AI-enabled) that are genuinely good.
And Google is getting back into Smart Glasses. If they succed with glasses, they have the added benefit of potential integration with Android phones, Chromebooks et al.
OpenAI just hired Apple’s device design guru Jony Ive and his team to build AI devices.
The crazy part is that all three own their LLMs.
And Apple doesn’t.
My friends who know Apple say it’s a long shot Apple makes a move (they’re too siloed and sensitive to data privacy).
Amazon
Amazon has a bigger moat than Apple here.
They have Amazon Bedrock (access to 3rd party LLMs (OpenAI, Claude et al)) and their own small LLMs. They can pacakage all this up with their AWS solutions.
They also own a stake in Anthropic (arguably the #3 LLM by marketshare).
They already hedge their bets by building their own LLMs (Titan, Nova and Olympus).
Maybe they’ll build one more “Transparent LLM”.
IBM
IBM is part way there with their IBM’s Granite 3.0 model (which has the initial transparent dataset).
But IBM would have to add premium content and create a revenue share with content companies.
They could nail the rev share (and the interface) part by being a surprise bidder for Perplexity (to get their Publishers Program).
Whatever they do, my guess is that IBM will stick to focusing on serving the enterprise (their bread and butter).
2) The Big 5 LLMs’ “Eat their Young”
The “Frontier Five” major LLMs (OpenAI, Google, Meta, Anthropic and X.ai) can also build a transparent LLM.
It’s what marketers call a “Multi-brand” strategy (aka “Eat Your Young”).
Building a Cheer to their Tide.
P&G is famous for this (they own detergent brands Tide, Gain, Cheer, Dreft and don’t care which one is #1 as long as one of them is!).
OpenAI and Google seem most likely to copy this play:
They could announce a fully open-sourced/transparent LLM as an alternative to their current LLM brand (ChatGPT and Gemini, respectively).
OpenAI or Google could create a new LLM that would be the Cheer to their Tide.
Anthropic seems less likely to Eat their Young given lower resources. But they are the LLM with the least resources and they might find themselves Napsterized.
Meta and x.Ai are wildcards here. Zuck and Elon are so bold and smart that I could see either spending $10 bil. to kickstart a new transparent LLM.
They also might wait to buy a startup (see below) who creates such an LLM first.
A Bold New Startup that Looks Like This
Finally, a new startup could build this new transparent LLM.
I don’t see them doing it alone.
Instead, the startup would need a headstart with legitimate content and investment.
Look for this startup to emulate the model of these 3 successful startups:
Vevo
Startup angle: Launched as a UMG joint venture with a startup-style team (ex-Yahoo and media execs)
Content contributed: Official music videos, mostly VEVO-branded
Big cos involved: Universal, Sony, Warner—all licensed their artist video catalogs
Business model: Ad-supported—YouTube ads, CTV pre-rolls, branded sponsorships; revenue shared with labels
PressReader
Startup angle: Founded by Alexander Kroogman; built the tech, apps, and licensing platform
Content contributed: Full newspaper and magazine editions, ready for digital reading
Big cos involved: The Guardian, LA Times, Newsweek, Le Figaro, The Washington Post, 7,000+ others
Business model: B2B and B2C subscriptions; revenue shared with publishers based on reads
Fandango
Startup angle: Built by a startup team led by Art Levitt (ex-Disney); acquired by NBCUniversal in 2007
Content contributed: Real‑time listings from ~31,000 U.S. screens, official showtimes, ticket inventory
Big cos involved: AMC, Regal, Cinemark, plus smaller theater chains
Business model: Per-ticket fees from users; affiliate fees; upsells (concessions, streaming, etc.)
Final Takeaways
For Content/Media Execs:
Push for 70/30 Rev Share — Demand the iTunes model: majority cut for creators.
Negotiate for Visibility, Not Just Cash — Footnotes, links, and in-product credit can drive traffic and awareness. Don’t leave distribution on the table.
For AI Execs:
Turn Lawsuits into a Moat — Build an LLM with licensed data, clear sourcing. You’ll win over publishing partners with this have the option to offer IP indemnity. That turns legal risk into enterprise trust.
Buy the “Golden Content” Now — Lock in deals with top publishers, studios, and experts before prices spike or regulators step in.
Distribution is Survival — Bundle your LLM inside hardware, OSs, and APIs. Like Apple with iTunes or Google with default search, ubiquity beats quality.
JV with Media Companies — One path to creating a unique new LLM is to do strategic partnerships with large content/distribution co.s (a la Vevo, PressReader and Fandango).
Thanks for reading!
Rob Kelly, Creator & Host of Media & the Machine
p.s.: How to reach me:
The best way to reach me is to subscribe below (it’s free). You can then reply to my emails (or comment). I read every reply. Thx again!