

The 14 Datasets DeepSeek Likely Used to Train Its AI (Zero Content Deals?)
I wanted to know how DeepSeek acquired its awesome content so I went digging.

On the heels of my AI Content Licensing Report last week, I wanted to find out how DeepSeek gets its awesome content.
DeepSeek doesn’t disclose its training data sources.
I reached out to them and their parent company (High-Flyer) to comment on this article. They haven’t responded.
10-Second Summary of this Post
DeepSeek's model is 14% larger than ChatGPT-4 (14.8T vs 13T tokens), but slightly smaller than Meta's Llama 3 (15T tokens)
DeepSeek hasn’t disclosed its training data sources but likely scraped from 14+ known datasets.
No signs of content licensing (e.g., like OpenAI/News Corp and Google/Reddit deals)
Distillation concerns: OpenAI suspects DeepSeek extracted ChatGPT data.
Deepseek Uses Mixture of Experts (MoE) & Reinforcement Learning (RL) for efficiency and reasoning.
DeepSeek’s Dataset is About 14% Larger than ChatGPT 4
First, a bit about the size of DeepSeek’s dataset.
To keep things simple, I’m analyzing mostly DeepSeek-V3. I’ll point out any differences between V3 and their R1 model (which is V3+ reasoning) where it matters.
DeepSeek is trained on 14.8 trillion “high-quality and diverse tokens”, according to the DeepSeek Technical Report (arXiv).
That’s about 13.8% larger than ChatGPT-4’s reported 13T tokens as leaked in the article “GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE” from Dylan Patel & the team at SemiAnalysis!.
Meta’s Llama 3 still edges out DeepSeek with 15T tokens.
Token size isn’t everything, but it matters.
14 Possible Datasets DeepSeek Used
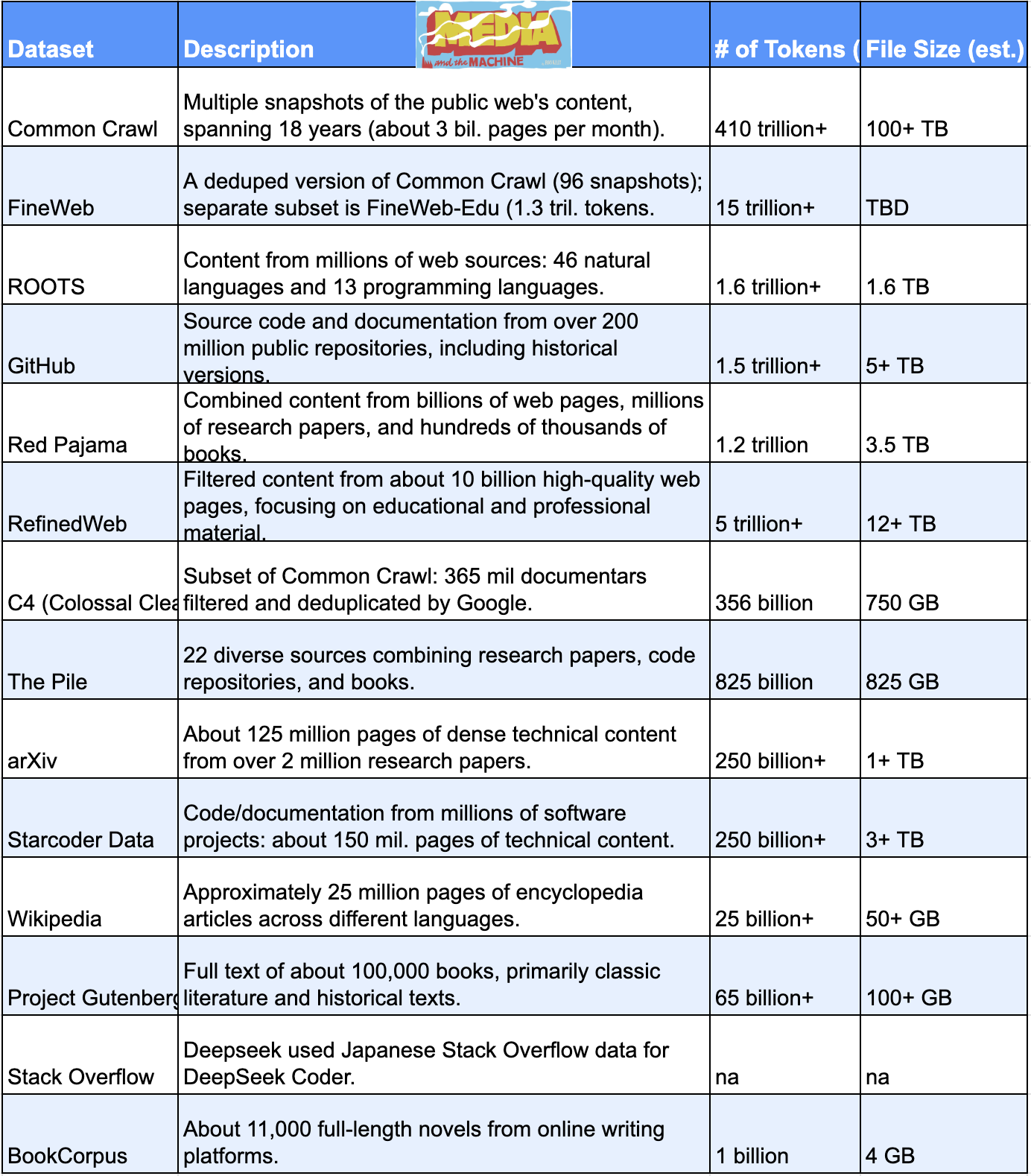
Note: some datasets, such as RefinedWeb, FineWeb, and The Pile, are subsets of Common Crawl.
Pre-Training Data (the initial datasets)
To get their data/content, Deepseek likely scraped the sh*t out of the Web.
The 14 datasets above are among the most likely they used.
This is an informed estimate.
I got my list by looking at what types of datasets other LLMs have used including their sizes.
Thanks to these kinds folks for their help:Kili's Open-Sourced Training Datasets for Large Language Models (LLMs), commoncrawl.org, BigScience Workshop, Together AI GitHub, Google Research/T5 paper, EleutherAI GitHub, arxiv.org, HuggingFace C4 wikipedia.org dumps, gutenberg.org, Hugging Face Japanese Stack Overlfow).
I also talked to/listened to a couple of LLM pros.
And then I asked the latest versions of ChatGPT, Gemini and DeepSeek itself what DeepSeek’s most likely data sources are.
DeepSeek Pulls a Page from the Playbooks of OpenAI, Google, Meta et al
This data acquisition process the same approach as other frontier models used.
For example, OpenAI used these datasets for its breakthrough ChatGPT-3.
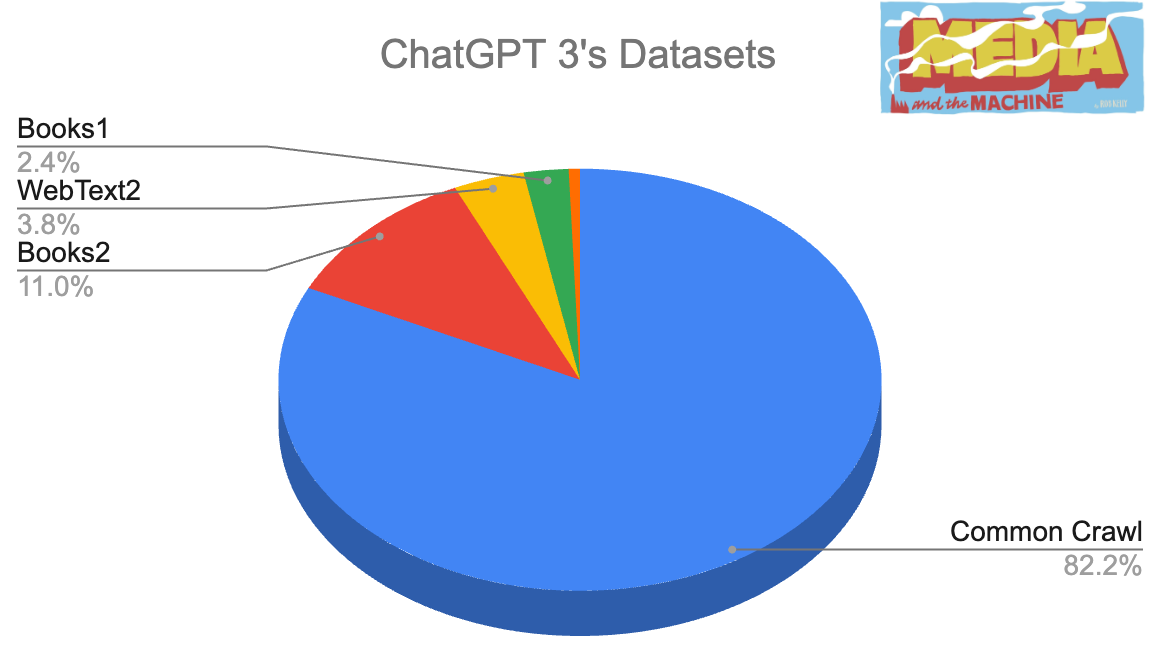
And Google used the deduped subset of CommonCrawl called “C4” for its models.
The LLMs used mostly the same data to start, though now they share less and less as they get larger (e.g. OpenAI doesn’t talk about specifics for GPT-4).
Deepseek Might Have Used “Shadow Libraries” like LibGen
It’s possible that DeepSeek trained on “shadow libraries
shared one thought on a DeepSeek data source this in his interview with Patrick O’Shaughnnessy on Invest Like the Best:And so one of the theories is DeepSeek trained…for example, there's these websites with names like Libgen that are basically giant Internet repositories of pirated books.
I myself would never use Libgen, but I have a friend who uses it all the time. It's like a superset of the Kindle store. It's got like every digital book and it's up there as a PDF and you can download it for free.
It's like Pirate Bay for watching movies or something.
The US labs might not feel like they can just basically download all the books from Libgen and train on it, but maybe the Chinese labs feel like they can. So there's potentially differential advantage there.
DeepSeek might not be alone.
Meta is on trial for using LibGen and other copyrighted material. There are emails suggesting Meta used LibGen and that Mark Zuckerberg approved it.
The Mixture of Experts (MOE)
DeepSeek also uses the MOE approach — it works like a team of helpers.
Each helper is good at one thing, just like how some folks are great at math while others are great at spelling.
When the computer needs to solve a problem, it picks the right helpers for that job. It doesn't use all the helpers at once - just the ones it needs.
This makes the computer work faster and better.
It also makes the model a lot cheaper to run.
To do this, DeepSeek first showed it lots and lots of words and information (e.g. the 14 datasets).
DeepSeek’s Custom Crawler
After the initial free data sources like the ones in the table above, DeepSeek likely switched to their own web crawler to get more content.
That’s something “most frontier labs do”, says
of Internconnects in the interview he and Dylan Patel did with Lex Friedman. writes the SemiAnalysis newsletter.Did DeepSeek license any content from content publishers?
If you read my 5 Takeaways from the AI Content Licensing Deals I'm Tracking report, you might be wondering if DeepSeek (like OpenAI, Google, Microsoft and Meta) paid the similar $tens of millions to acquire any of its content (e.g. from Reddit, News Corp., Shutterstock, Axel-Springer, etc.).
I don’t see any sign of that.
And I’ve looked.
But, DeepSeek can certainly afford it.
Their parent company, High-Flyer, has $7 bil. in assets under management (source: Wikipedia).
And Liang Wenfeng (founder and CEO) of both DeepSeek and High-Flyer reportedly has a controlling interest in both.
If so, he’d be able to move very fast with any publisher.
Post-Training Data Usage
Here’s where things get a little more interesting.
Did DeepSeek use ChatGPT’s data to train its model?
OpenAI & the U.S. Government claim foul play (“Distillation”)
OpenAI told the Wall Street Journal that it’s looking at indications that DeepSeek “extracated large volumes of data from OpenAI’s tools” using a process called “Distillation” (see “OpenAI Is Probing Whether DeepSeek Used Its Models to Train New Chatbot”).
Donald Trump’s AI Czar
elaborated on this in this interview with Fox News:“There is a technique in AI which is called distillation which you will hear a lot about. It’s when another model learns from another one.
What happens is the student model asks the parent model a lot of questions just like a human would learn…
…They learn from the parent model and suck the knowledge out of the parent model.
There is substantial evidence that what DeepSeek did here is they distilled the knowledge out of OpenAI’s models. I don’t think they are happy about it.”
— David Sacks, AI Czar of the United States
It’s unclear if this case of distillation is illegal or just a violation of OpenAI’s terms of service.
Did DeepSeek infringe on OpenAI’s content?
As Lambert and Patel discussed with Lex, unless DeepSeek signed a software license with OpenAI (penalty: copyright infringement) it’s possible that all DeepSeek did was violate the Terms of Service for ChatGPT.
The penalty for a TOS violation would likely be that a DeepSeek employee gets booted off ChatGPT).
Publishers: “Oh, the irony!”
Oh the irony, some publishers are saying.
Publishers claim OpenAI and other LLMs stole content from them.
The following are publishers filing copyright infringement lawsuits (or cease and desist letters) against AI companies:
The New York Times
Forbes
The Chicago Tribune
The New York Post
The Daily News
The Center for Investigative Reporting
Authors (John Grisham, Jodi Picoult, George R.R. Martin, Andrea Bartz, Charles Graeber and Kirk Wallace Johnson)
Right now, I find GPT is Eating the World to be the best resource to follow AI/Publisher lawsuits.
Supervised Fine-Tuning (SFT)
Next, to make its data even better, DeepSeek likely used SFT.
It’s the human-assisted approach to train a model on labeled data.
An example of SFT might be to match a prompt/question like:
"When did the Black Monday stock market crash occur?"
…with a response like:
"October 19, 1987."
A human approves if if it’s correct.
Reinforcement Learning (RL)
Next, DeepSeek likely used reinforcement learning (RL) (at least for DeepSeek-R1, their reasoning model).
Think of it like this:
At this point, the LLM is like a strong athlete with great physical potential.
Now, that athlete needs specialized coaching (RL) to become a champion in a specific sport (reasoning).
Reinforcement Learning from Human Feedback (RLHF)
While DeepSeek's V-3 uses some RHLF, its R1 model is quite different.
It utilizes a fully automated reinforcement learning process without relying on human feedback.
It uses automated rule-based reward functions to improve its reasoning capabilities through self-generated feedback.
Final Takeaways
For Content Owners:
DeepSeek is officially the newest AI giant training on web content—likely without licensing much of it. If you're a publisher, this reinforces the need to have a strategy for every major LLM.
For AI Executives:
DeepSeek is playing by the same playbook as OpenAI, Google, and Meta, but with added controversy. The accusations of distilling ChatGPT's data put them in murky legal territory, but I doubt OpenAI will sue. If you're in AI, this is a case study on the fine line between innovation and IP risk.
Thanks for reading!
Rob Kelly, Creator & Host of Media & the Machine
p.s. How to reach me?
If you want to reach me, the best way is to subscribe below and reply to any of my emails. There’s a free option — and your reply comes directly to my inbox.